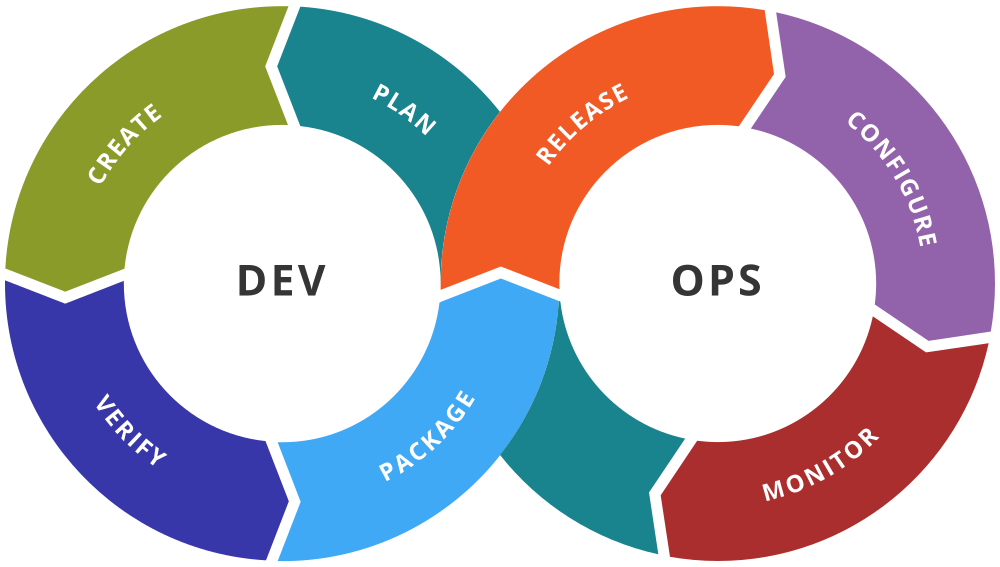
 DevOps is widely regarded as a natural progression of agile development practices and lean principles. As the values from both were applied to software development and project management, it eventually became apparent that the same values could be applied to IT operations.
DevOps is widely regarded as a natural progression of agile development practices and lean principles. As the values from both were applied to software development and project management, it eventually became apparent that the same values could be applied to IT operations. This gathering helped spawn the dozens of agile tools, methodologies and frameworks that exist today. Some of the more popular ones include
This gathering helped spawn the dozens of agile tools, methodologies and frameworks that exist today. Some of the more popular ones include How do we answer how long it will take to add a new feature, fix a bug or change a workflow in an application? We often provide answers in terms of how long it takes to complete the development work alone, all while ignoring the total time required to complete the request before and after the actual "work" takes place.
In the Lean Value Stream Map, Process Time (PT) is the time it takes to do the work. Lead Time (LT) includes the Process Time and everything else outside of that for that step. In the case of software development this can include time for ideation, QA testing, deployment time, etc.

Image copyright 2016 The Karen Martin Group, Inc.
Deployment lead time at a typical corporation can be weeks or even months. This is because deployment is often more complex than just dropping some code onto a server or running an upgrade overnight. We are now forced to consider the time “required” to provision a server, or cutover into a new environment, or meet some other requirement that is necessary for deployment in the infrastructure's current state.
Have you ever found yourself asking “Why does it take so long to get a server?” I have been asking that question for over a decade. Every time I go to a customer that builds applications for large teams deployment is a large undertaking. It seems like the wheel keeps getting reinvented each time. (We'll cover some tools that help teams solve these problems in a future article.)
A Common Scenario: Multi-Month Deployment Lead Times
Many large organizations support monolithic apps that rely heavily on manual testing. These apps often have minimal test environments that require a lot of time to set up & manage. If you were to create a Value Stream Map of the development and deployment process it would be incredibly complex.
What happens in these scenarios? Completing work can - and usually does - require heroics from your teams at all stages of the development and deployment processes. Fixing problems in the application can require days or weeks of effort. That effort usually results in poor outcomes for your customers. It's not a recipe for success.
An Ideal Scenario: Multi-Minute Deployment Lead Times
What if we strove for fast, constant feedback on our work? What if every dev team did small atomic code changes? Wouldn’t it be nice to have automated testing in the application so the QA team could concentrate on the hard problems? How about regular code deployments into Production on a weekly, daily or hourly basis? What would the Value Stream Map look like in this scenario? Certainly it should be much simpler.
Let's consider the outcomes in this scenario. For starters, shorter lead times enable a high degree of confidence in changes introduced into the application. No longer do your development and ops teams live in fear of breaking existing features or losing customer confidence. Agile development practices and automated testing regimes passively drive development teams to build modular, loosely coupled architectures so small teams can work with a high degree of autonomy. With smaller changes that are tested and pushed regularly, failures that do get through tend to be smaller and more contained.
Initial Metrics To Begin With
What are some metrics to start measuring to determine where pain points are prior to starting or monitoring your DevOps journey? A few suggestions...
- Lead Times - As previously discussed, the total time from when a request is made to when it is deployed.
- Process Times - Limited to the time it takes to complete the development of the feature or fix.
- Percent Complete and Accurate - For a given Value Stream Map step (ie. coding/unit testing, UAT testing, etc.) this is the percent of Complete/Accurate work items received from the previous step in the Value Stream Map.
The 3 Ways: The Principles Underpinning DevOps
In the book The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win, the authors mention “The 3 Ways” as principles that they have found involved in all successful DevOps practicing organizations. I will briefly cover them and we can go into more detail in future articles.
1st Way: Flow of Work

We should first strive to have fast flow of work, per our Value Stream Map, from development to operations to your customers.
2nd Way: Feedback

What good is running really fast in a direction if you don’t provide fast and constant feedback from the right to the left at all stages of our Value Stream Map?
3rd Way: Continuous Learning & Experimentation

Flow and feedback at all stages of the Value Stream Map can then allow you to create a culture of continuous learning and experimentation. This allows your teams to innovate, share their learnings, experiment on new ideas without fear of retribution, and contribute to moving the organization forward on all levels.
The First Way of DevOps: Flow
In the previous article, we started talking about DevOps principles and stopped after a brief introduction to “The 3 Ways” as mentioned in the book The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win. We’ll be continuing on by talking about the first way, Flow.
.jpg?t=1541976685264)
What Do We Mean By Flow?
When we look at the Value Stream Map, we should consider the performance of the entire system we’re in, not just a specific department or team within our organization. Focusing on a little silo won’t give us enough perspective on where bottlenecks are or where improvements can be made across the system as a whole.
We should understand the flow of work in our value stream. Work can originate from features, defects, requirements from other teams (InfoSec, Legal, etc), support tickets, etc. Your value stream should always be moving forward. If you identify areas where flow is going backwards in your value stream, that should be treated as a problem that needs addressed.
As The Ford Motor Company says, “Quality if Job Number 1.” All members of the organization that participate in the value stream should focus on improving quality. Most of us would like to only do something once. Sometimes that is not always the case. What is important is making rework visible and accountable. If the individuals causing rework don’t “feel the pain” then they are likely to continue impeding flow and any fixes they contribute are unlikely to correct the cause of the rework.
The key lies in having a deep understanding of your system. In a Systems Thinking approach, this doesn't mean that the smartest person in the room knows everything. High-performing organizations will lean on collective intelligence. You need to have a foundation of knowledge in order to make informed decisions. Deming referred to this as “Appreciation of the System.”
What Are Some Things That Interfere With Flow?
Visibility
Visibility around problems and processes can be an issue. Software development work is often "invisible" because there is no tangible product you can hold in your hands. Where is flow being impeded in your current processes? Do you know if there are any work constraints?
You should strive to make work as visible as possible. I’m not talking about all the developers using giant screens with large fonts. Large visual work boards are one way. An Obeya, or visual room, is another way.
A good place to start is a simple idea board. Have individuals put up ideas to make their own work easier or faster. It may not immediately “move the needle” but the idea here is to get everyone comfortable with making their ideas visible to both peers and leadership in the organization.

Involving individuals in establishing qualitative and quantitative measurements for each process in the Value Stream will help organize a visual board. For example, departments within an organization may decide that they want to practice the 5Ss and want to track how well the department is doing.
Controlling the signal to noise ratio of your visual communication will go a long way in being useful to the organization.
Beware, though... an organization can get carried away with metrics and measurements for their visual boards & rooms. Controlling the signal to noise ratio of your visual communication will go a long way in being useful to the organization. Identifying critical success factors that help the organization reach yearly goals allows the collective to select the process measurements that can be visualized to radiate progress towards those goals.
Dynamic WIP
WIP, or Work In Progress, varies from team to team and organization to organization. In the case of software development organizations, interrupting developers is easy. The consequences of the interruptions are generally invisible. Aso, something as simple as being on multiple projects at a time actually decreases efficiency and raises risk.
One way to help with this problem is to limit the WIP for project teams. A simple visual way of doing this is with a Kanban Board. The project team can define, agree on, and enforce WIP limits on each column of the board. This makes it easier for everyone on the project team, and others that may just be passing through the project team space, to see problems that prevent completion of work.
Long Development Cycles
Many organizations tend towards long development cycles. This can be anywhere from 6-24 months of development before user feedback is solicited. Some would argue that 2 months is too long for this.
One of the causes of long development cycles, especially within very large organizations, is BRUF and Analysis Paralysis. Then, once you get past that, the developers work first, then testing comes later. The testers test everything - regression, integration, edge cases. Then, some day, the code sees the light of day and gets into a Production environment that the customer is allowed to access. This is where the organization figures out if they even built the right thing or not.

Clearly, this is not a sustainable approach, but it is a pretty common one. How do we change this approach in order to increase our flow? One way is to look at implementing a GRITapproach. Rather than documenting All The Things at the beginning, we can (and should) treat requirements gathering as an iterative process slightly ahead of the development iterations.
Instead of relying on a QA team or department to do all of the testing, the developers can adopt the practices of TDD and ATDD as part of their workflow. This would then allow for automated unit & integration tests which would free up dedicated QA to focus solely on edge cases and the “hard” problems that can only be found via manual testing as the “easy” stuff is now found prior to anything reaching QA.
Restructuring how you handle requirements gathering and managing code testing are just two ways to cut down on the development cycle time. This will allow the organization to deploy to Production sooner.
Getting Code Into Higher Environments
How long does it typically take for a development team to push their code to Production? Are multiple departments involved? There could be hundreds or thousands of operations between the code entering into source control and the final deployment into Production. Depending on the number of individuals involved, there is N(N-1) / 2 possible communication paths in the project. If you think about it, if multiple teams are involved in the deployment of software to Production, it can be kind of like the game of Telephone.
How can we mitigate these kinds of problems? If we can reduce the number of handoffs, that would increase our flow. Automating portions of the work (code build, code deployment, server configuration, etc) can certainly help. Also helpful: reorganizing project teams so that they can be cross-functional to directly deliver value themselves versus having many external teams that are relied upon.
Other Project Barriers
Partially done work, extra unintended features, task switching due to changing priorities, defects found later in the development cycle, and team heroics can all contribute to impeding flow.
So, what can we do? Being introspective and looking to eliminate waste in our value stream can help. Partially done work loses value over time. The idea of “gold plating” generally adds complexity & testing effort and thus should be actively thwarted. Using TDD/BDD/ATDD techniques to shorten the time between defect creation & detection can diminish the difficulty of resolution. Lastly, don’t put your teams into a position where unreasonable acts become the norm.